Auto-Tagging in OpenDataLoader PDF: How Visual Integrity Is Guaranteed
Posted on 2026-06-04 by julia.katash@duallab.com in Computers, Consumer Services, Education, Electronics, Government, Human Resources, Internet & Online, Management, Software, Technology, Telecommunications // 0 Comments
London, Great Britain, 2026-06-04 — /EPR Network/ —

OpenDataLoader’s auto-tagging guarantees that the document remains visually unchanged because it separates structure from presentation.
How do we do it?
The Core Principle: Tags vs. Visuals
PDFs are ambivalent documents. They contain:
- A visual layer: the exact positioning of text, images, and graphics on each page.
- A structural layer (optional): tags that describe what each element means (heading, paragraph, table, etc.)
Untagged PDFs have only the visual layer. When screen readers encounter these, they see a mess of text with no hierarchy like reading a magazine where someone has cut every article into individual words and thrown them on a table.
Auto-tagging adds the structural layer without touching the visual layer. It’s like adding an invisible table of contents and semantic labels to a book without changing a single word on the pages.

How OpenDataLoader Preserves Visual Integrity
1. Structure is written, not rendered
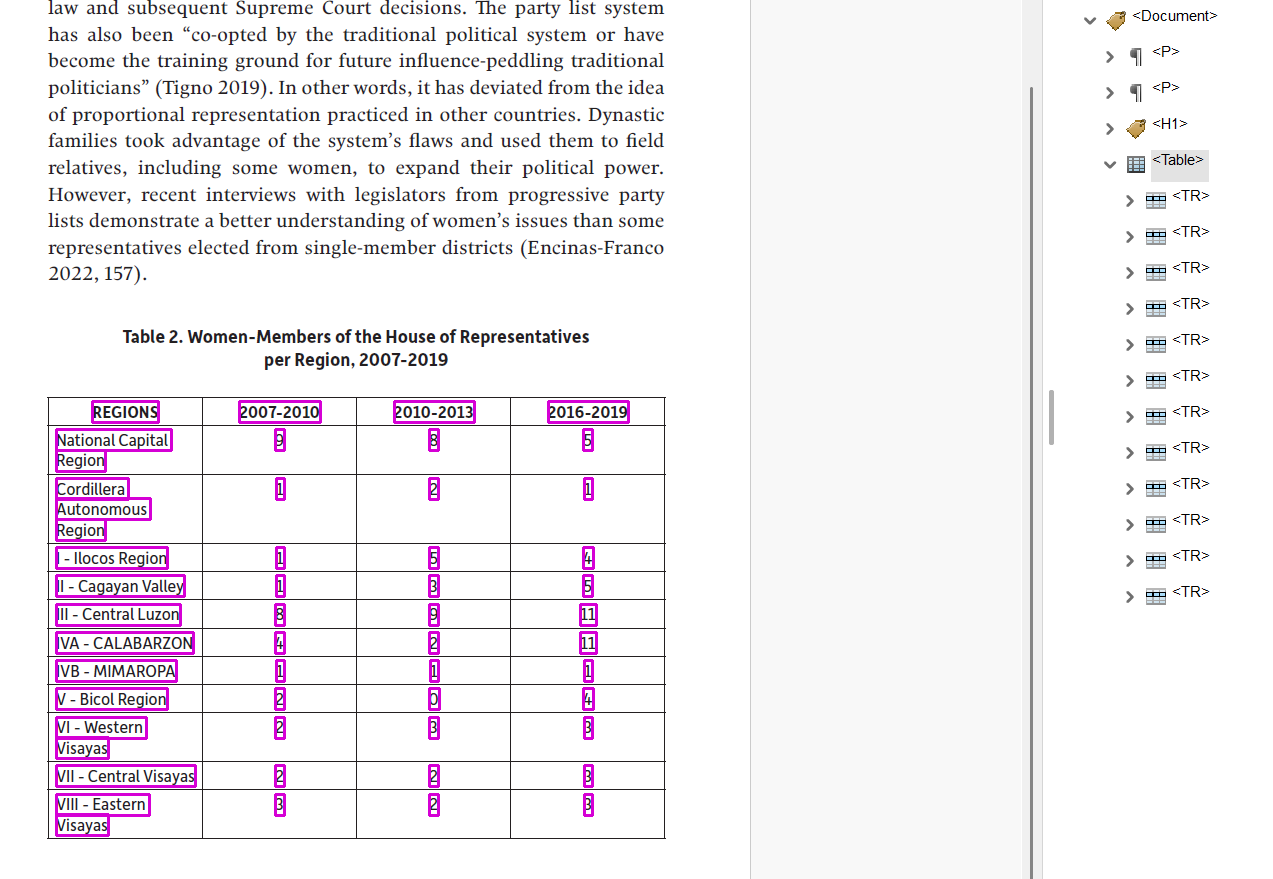
OpenDataLoader’s auto-tagging engine analyzes the document’s layout, detecting headings by visual text properties, identifying tables by grid patterns, recognizing lists by bullet positions and then writes this structural information directly into the PDF’s internal structure tree.
Critically, this structural information exists alongside the existing visual instructions, not instead of them.
The tags are simply additional data that assistive technologies can use.
2. The Guarantee of preserve appearance
OpenDataLoader produces a screen-reader-ready PDF with structure tags (headings, paragraphs, lists, tables, reading order). The output is a Tagged PDF, not a reformatted or redrawn document.
This means:
- No repositioning: text stays exactly where it was
- No reformatting: fonts, spacing, and layout remain identical
- No content removal: everything visible stays visible
- No visual additions: tags are invisible metadata.
3. Validated against industry standards

OpenDataLoader’s auto-tagging was built in collaboration with the Dual Lab (Member of PDF Association, supports veraPDF, developers of PDF4WCAG Accessibility checker).
4. Two Engine Options for Accuracy
OpenDataLoader offers two processing modes:
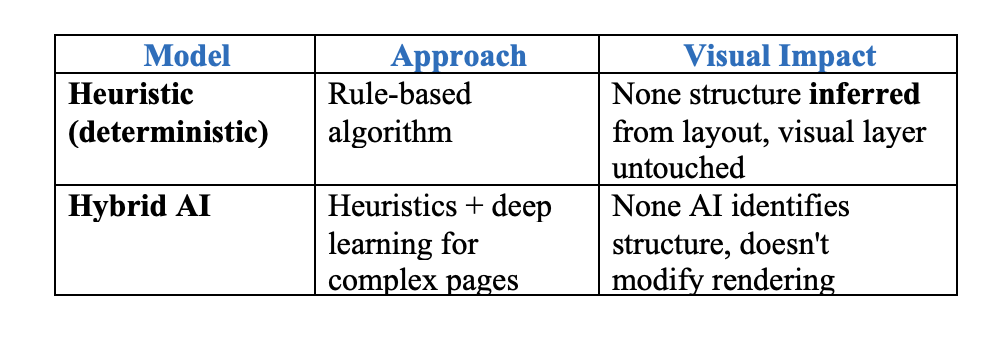
Both modes operate on the same principle: analyze the visual layer, infer structure, write tags. Neither mode alters the underlying visual instructions.
How Hybrid Mode Works for Auto-Tagging
Hybrid mode combines fast local Java processing with AI backends. Simple pages stay local (0.02s); complex pages route to AI for +90% table accuracy.
Simple pages — processed locally (approximately 0.02s per page)
Complex pages — routed to AI backend for enhanced accuracy
What Hybrid Mode Enables
Hybrid mode specifically handles content types that deterministic local processing struggles with:

Accuracy Improvements
The results show dramatic accuracy improvements with hybrid mode:
- Table extraction accuracy: Jumps from 0.489 (local mode) to 0.928 (hybrid mode)
- Overall benchmark score: 0.907 overall #1 overall, leading in reading order (0.934) and table extraction (0.928)
- Reading order accuracy: 0.934
OpenDataLoader’s auto-tagging preserves visual integrity by design. The technology adds semantic structure without touching the presentation layer, follows industry specifications validated by PDF accessibility experts, and has been built specifically to solve the accessibility problem without creating new ones.
Matched content
Editor’s pick
- Digi Communications NV announces framework agreement entered into by the Company’s Romanian subsidiary
- AI-POWERED VOICE HEADSET TECHNOLOGY SET TO TRANSFORM STORE OPERATIONS FOR GERMAN RETAILERS
- Digi Communications NV announces decision of the National Authority for Management and Regulation in Communications (ANCOM)
- Digi Communications NV announces 2026 AGM convocation
- Digi Communications NV announces availability of Q1 2026 financial report
- Digi Communications NV announces investors call for the presentation of the Q1 2026 financial results
- Digi Communications N.V. announces an amendment to the 2026 Financial Calendar
- Digi Communications N.V. announces availability of the Romanian-language ESEF version of the 2025 Annual Report
- Digi Communications N.V. announces availability of the non-statutory consolidated financial statements of Digi Romania S.A. for the year ended 31 December 2025
- Digi Communications N.V. announces availability of 2025 Financial report
- Digi Communications N.V. announces 2025 Financial Year dividend proposal
- Gestionar proyectos de IA con confianza: el PMI lanza la certificación PMI-CPMAI en español, que ofrece pasos prácticos para llevar a cabo con éxito proyectos de IA a los profesionales del sector en España
- Digi Communications N.V. announces status update on the potential Digi Spain Telecom S.A.U. transaction
- Digi Communications N.V. announces registration of the financial instruments resulting from the share capital increase
- Orivante Holdings Deploys AI Tools to Broaden Investor Access in Litigation Finance
- Free ICT Europe Warns of “Sovereignty Gap” in Enterprise ICT
- Europeans demand control over their digital identity
- Digi Communications N.V. announces Decision of the Board of Directors regarding the issuance of new shares
- Digi Communications N.V. announces acquisition of a 51% shareholding in Whyfibre Limited
- Digi Communications N.V. announces extraordinary general meeting’s resolution from 20 March 2026, approving the authority of the Board to issue shares on account of the Company’s retained earnings and general reserves and partially amend the Company’s articles of association
- Proteins Mosaic Q: a citizen-science project to gather evidence for a novel 3D protein structural pattern
- Digi Communications N.V. announces Registration with the FSA of the financial instruments resulting from the conversion of 16,974 A shares into an equal number of class B shares
- Digi Communications NV announces update regarding the live stream link for the Capital Markets Day 2026
- Samsung Electronics America selected EYEONIX’s COMMAND for Presentation in the United States
- Digi Communications NV announces Capital Markets Day 2026 Madrid
- Digi Communications N.V. reports preliminary consolidated revenues of 2,2 billion euros in 2025, a 15% year-over-year increase
- Digi Communications N.V. announces the resolution of the Board of Directors to convert class A shares into an equal number of class B shares for the purpose of distribution in accordance with an ongoing stock option plan
- Digi Communications NV announces Investors call for the presentation of the 2025 preliminary financial results
- Digi Communications N.V. announces Capital Markets Day 2026
- Digi Communications N.V. announces Convening of the Company’s general shareholders extraordinary meeting for 20 March 2026, for the approval of, among others, the authorization of the Board of Directors to issue shares
- EPP Pricing Platform announces leadership transition to support long-term continuity and growth
- BEISPIELLOSER SCHRITT: ZEE ENTERTAINMENT UK STARTET SEIN FLAGGSCHIFF ZEE TV MIT LIVE-UNTERTITELN IN DEUTSCHER SPRACHE AUF SAMSUNG TV PLUS IN DEUTSCHLAND, ÖSTERREICH UND DER SCHWEIZ
- Netmore Acquires Actility to Lead Global Transformation of Massive IoT
- Digi Communications N.V. announces the release of 2026 Financial Calendar
- Digi Communications N.V. announces availability of the report on corporate income tax information for the financial year ending December 31, 2024
- Oznámení o nadcházejícím vyhlášení rozsudku Evropského soudu pro lidská práva proti České republice ve čtvrtek dne 18. prosince 2025 ve věci důvěrnosti komunikace mezi advokátem a jeho klientem
- TrustED kicks off pilot phase following a productive meeting in Rome
- Gstarsoft consolida su presencia europea con una participación estratégica en BIM World Munich y refuerza su compromiso a largo plazo con la transformación digital del sector AEC
- Gstarsoft conforte sa présence européenne avec une participation dynamique à BIM World Munich et renforce son engagement à long terme auprès de ses clients
- Gstarsoft stärkt seine Präsenz in Europa mit einem dynamischen Auftritt auf der BIM World Munich und bekräftigt sein langfristiges Engagement für seine Kunden
- Digi Communications N.V. announces Bucharest Court of Appeal issued a first instance decision acquitting Digi Romania S.A., its current and former directors, as well as the other parties involved in the criminal case which was the subject matter of the investigation conducted by the Romanian National Anticorruption Directorate
- Digi Communications N.V. announces the release of the Q3 2025 financial report
- Lake George RV Park Named Best Overall and Best Pet-Friendly Campground in New York
- Digi Communications N.V. announces the admission to trading on the regulated market operated by Euronext Dublin of the offering of senior secured notes by Digi Romania
- Digi Communications NV announces Investors Call for the presentation of the Q3 2025 Financial Results
- Rise Point Capital invests in Run2Day; Robbert Cornelissen appointed CEO and shareholder
- Digi Communications N.V. announces the successful closing of the offering of senior secured notes due 2031 by Digi Romania
- BioNet Achieves EU-GMP Certification for its Pertussis Vaccine
- Digi Communications N.V. announces the upsize and successful pricing of the offering of senior secured notes by Digi Romania
- Hidora redéfinit la souveraineté du cloud avec Hikube : la première plateforme cloud 100% Suisse à réplication automatique sur trois data centers
- Digi Communications N.V. announces launch of senior secured notes offering by Digi Romania. Conditional full redemption of all outstanding 2028 Notes issued on 5 February 2020
- China National Tourist Office in Los Angeles Spearheads China Showcase at IMEX America 2025
- China National Tourist Office in Los Angeles Showcases Mid-Autumn Festival in Arcadia, California Celebration
- Myeloid Therapeutics Rebrands as CREATE Medicines, Focused on Transforming Immunotherapy Through RNA-Based In Vivo Multi-Immune Programming
- BevZero South Africa Invests in Advanced Paarl Facility to Drive Quality and Innovation in Dealcoholized Wines
- Plus qu’un an ! Les préparatifs pour la 48ème édition des WorldSkills battent leur plein
- Digi Communications N.V. announces successful completion of the FTTH network investment in Andalusia, Spain
- Digi Communications N.V. announces Completion of the Transaction regarding the acquisition of Telekom Romania Mobile Communications’ prepaid business and certain assets
- Sparkoz concludes successful participation at CMS Berlin 2025
- Digi Communications N.V. announces signing of the business and asset transfer agreement between DIGI Romania, Vodafone Romania, Telekom Romania Mobile Communications, and Hellenic Telecommunications Organization
- Sparkoz to showcase next-generation autonomous cleaning robots at CMS Berlin 2025
- Digi Communications N.V. announces clarifications on recent press articles regarding Digi Spain S.L.U.
- Netmore Assumes Commercial Operations of American Tower LoRaWAN Network in Brazil in Strategic Transition
- Cabbidder launches to make UK airport transfers and long-distance taxi journeys cheaper and easier for customers ↗️
- Robert Szustkowski appeals to the Prime Minister of Poland for protection amid a wave of hate speech
- Digi Communications NV announces the release of H1 2025 Financial Report
- Digi Communications NV announces “Investors Call for the presentation of the H1 2025 Financial Results”
- As Brands React to US Tariffs, CommerceIQ Offers Data-Driven Insights for Expansion Into European Markets
- Digi Communications N.V. announces „The Competition Council approves the acquisition of the assets and of the shares of Telekom Romania Mobile Communications by DIGI Romania and Vodafone Romania”
- HTR makes available engineering models of full-metal elastic Lunar wheels
- Tribunal de EE.UU. advierte a Ricardo Salinas: cumpla o enfrentará multas y cárcel por desacatoo
- Digi Communications N.V. announces corporate restructuring of Digi Group’s affiliated companies in Belgium
- Aortic Aneurysms: EU-funded Pandora Project Brings In-Silico Modelling to Aid Surgeons
- BREAKING NEWS: New Podcast “Spreading the Good BUZZ” Hosted by Josh and Heidi Case Launches July 7th with Explosive Global Reach and a Mission to Transform Lives Through Hope and Community in Recovery
- Cha Cha Cha kohtub krüptomaailmaga: Winz.io teeb koostööd Euroopa visionääri ja staari Käärijäga
- Digi Communications N.V. announces Conditional stock options granted to Executive Directors of the Company, for the year 2025, based on the general shareholders’ meeting approval from 25 June 20244
- Cha Cha Cha meets crypto: Winz.io partners with European visionary star Käärijä
- Digi Communications N.V. announces the exercise of conditional share options by the executive directors of the Company, for the year 2024, as approved by the Company’s OGSM from 25 June 2024
- “Su Fortuna Se Ha Construido A Base de La Defraudación Fiscal”: Críticas Resurgen Contra Ricardo Salinas en Medio de Nuevas Revelaciones Judiciales y Fiscaleso
- Digi Communications N.V. announces the availability of the instruction regarding the payment of share dividend for the 2024 financial year
- SOILRES project launches to revive Europe’s soils and future-proof farming
- Josh Case, ancien cadre d’ENGIE Amérique du Nord, PDG de Photosol US Renewable Energy et consultant d’EDF Amérique du Nord, engage aujourd’hui toute son énergie dans la lutte contre la dépendance
- Bizzy startet den AI Sales Agent in Deutschland: ein intelligenter Agent zur Automatisierung der Vertriebspipeline
- Bizzy lance son agent commercial en France : un assistant intelligent qui automatise la prospection
- Bizzy lancia l’AI Sales Agent in Italia: un agente intelligente che automatizza la pipeline di vendita
- Bizzy lanceert AI Sales Agent in Nederland: slimme assistent automatiseert de sales pipeline
- Bizzy startet AI Sales Agent in Österreich: ein smarter Agent, der die Sales-Pipeline automatisiert
- Bizzy wprowadza AI Sales Agent w Polsce: inteligentny agent, który automatyzuje budowę lejka sprzedaży
- Bizzy lanza su AI Sales Agent en España: un agente inteligente que automatiza la generación del pipeline de ventas
- Bizzy launches AI Sales Agent in the UK: a smart assistant that automates sales pipeline generation
- As Sober.Buzz Community Explodes Its Growth Globally it is Announcing “Spreading the Good BUZZ” Podcast Hosted by Josh Case Debuting July 7th
- Digi Communications N.V. announces the OGMS resolutions and the availability of the approved 2024 Annual Report
- Escándalo Judicial en Aumento Alarma a la Opinión Pública: Suprema Corte de México Enfrenta Acusaciones de Favoritismo hacia el Aspirante a Magnate Ricardo Salinas Pliego
- Winz.io Named AskGamblers’ Best Casino 2025
- Kissflow Doubles Down on Germany as a Strategic Growth Market with New AI Features and Enterprise Focus
- Digi Communications N.V. announces Share transaction made by a Non-Executive Director of the Company with class B shares
- Salinas Pliego Intenta Frenar Investigaciones Financieras: UIF y Expertos en Corrupción Prenden Alarmas
- Digital integrity at risk: EU Initiative to strengthen the Right to be forgotten gains momentum
- Orden Propuesta De Arresto E Incautación Contra Ricardo Salinas En Corte De EE.UU
- Digi Communications N.V. announced that Serghei Bulgac, CEO and Executive Director, sold 15,000 class B shares of the company’s stock
- PFMcrypto lancia un sistema di ottimizzazione del reddito basato sull’intelligenza artificiale: il mining di Bitcoin non è mai stato così facile
- Azteca Comunicaciones en Quiebra en Colombia: ¿Un Presagio para Banco Azteca?
- OptiSigns anuncia su expansión Europea
- OptiSigns annonce son expansion européenne
- OptiSigns kündigt europäische Expansion an
- OptiSigns Announces European Expansion
- Digi Communications NV announces release of Q1 2025 financial report
- Banco Azteca y Ricardo Salinas Pliego: Nuevas Revelaciones Aumentan la Preocupación por Riesgos Legales y Financieros
- Digi Communications NV announces Investors Call for the presentation of the Q1 2025 Financial Results
- Digi Communications N.V. announces the publication of the 2024 Annual Financial Report and convocation of the Company’s general shareholders meeting for June 18, 2025, for the approval of, among others, the 2024 Annual Financial Report, available on the Company’s website
- La Suprema Corte Sanciona a Ricardo Salinas de Grupo Elektra por Obstrucción Legal
- Digi Communications N.V. announces the conclusion of an Incremental to the Senior Facilities Agreement dated 21 April 2023
- 5P Europe Foundation: New Initiative for African Children
- 28-Mar-2025: Digi Communications N.V. announces the conclusion of Facilities Agreements by companies within Digi Group
- Aeroluxe Expeditions Enters U.S. Market with High-Touch Private Jet Journeys—At a More Accessible Price
- SABIO GROUP TAKES IT’S ‘DISRUPT’ CX PROGRAMME ACROSS EUROPE
- EU must invest in high-quality journalism and fact-checking tools to stop disinformation
- ¿Está Banco Azteca al borde de la quiebra o de una intervención gubernamental? Preocupaciones crecientes sobre la inestabilidad financiera
- Netmore and Zenze Partner to Deploy LoRaWAN® Networks for Cargo and Asset Monitoring at Ports and Terminals Worldwide
- Rise Point Capital: Co-investing with Independent Sponsors to Unlock International Investment Opportunities
- Netmore Launches Metering-as-a-Service to Accelerate Smart Metering for Water and Gas Utilities
- Digi Communications N.V. announces that a share transaction was made by a Non-Executive Director of the Company with class B shares
- La Ballata del Trasimeno: Il Mediometraggio si Trasforma in Mini Serie
- Digi Communications NV Announces Availability of 2024 Preliminary Financial Report
- Digi Communications N.V. announces the recent evolution and performance of the Company’s subsidiary in Spain
- BevZero Equipment Sales and Distribution Enhances Dealcoholization Capabilities with New ClearAlc 300 l/h Demonstration Unit in Spain Facility
- Digi Communications NV announces Investors Call for the presentation of the 2024 Preliminary Financial Results
- Reuters webinar: Omnibus regulation Reuters post-analysis
- Patients as Partners® Europe Launches the 9th Annual Event with 2025 Keynotes, Featured Speakers and Topics
- eVTOLUTION: Pioneering the Future of Urban Air Mobility
- Reuters webinar: Effective Sustainability Data Governance
- Las acusaciones de fraude contra Ricardo Salinas no son nuevas: una perspectiva histórica sobre los problemas legales del multimillonario
- Digi Communications N.V. Announces the release of the Financial Calendar for 2025
- USA Court Lambasts Ricardo Salinas Pliego For Contempt Of Court Order
- 3D Electronics: A New Frontier of Product Differentiation, Thinks IDTechEx
- Ringier Axel Springer Polska Faces Lawsuit for Over PLN 54 million
- Digi Communications N.V. announces the availability of the report on corporate income tax information for the financial year ending December 31, 2023
- Unlocking the Multi-Million-Dollar Opportunities in Quantum Computing
- Digi Communications N.V. Announces the Conclusion of Facilities Agreements by Companies within Digi Group
- The Hidden Gem of Deep Plane Facelifts
- KAZANU: Redefining Naturist Hospitality in Saint Martin
- Enjoy Up to 35% Off MovPilot Video Downloaders this Black Friday
- New IDTechEx Report Predicts Regulatory Shifts Will Transform the Electric Light Commercial Vehicle Market
- Almost 1 in 4 Planes Sold in 2045 to be Battery Electric, Finds IDTechEx Sustainable Aviation Market Report
- Up to 50% Off TuneFab Music Converters with Coupon Code 2024
- Digi Communications N.V. announces the release of Q3 2024 financial results
- Digi Communications NV announces Investors Call for the presentation of the Q3 2024 Financial Results
- Pilot and Electriq Global announce collaboration to explore deployment of proprietary hydrogen transport, storage and power generation technology
- Digi Communications N.V. announces the conclusion of a Memorandum of Understanding by its subsidiary in Romania
- Digi Communications N.V. announces that the Company’s Portuguese subsidiary finalised the transaction with LORCA JVCO Limited
- Richard Reid Partners with Goodspace Anxiety Aid In Support of International Men’s Day
- Digi Communications N.V. announces that the Portuguese Competition Authority has granted clearance for the share purchase agreement concluded by the Company’s subsidiary in Portugal
- OMRON Healthcare introduceert nieuwe bloeddrukmeters met AI-aangedreven AFib-detectietechnologie; lancering in Europa september 2024
- OMRON Healthcare dévoile de nouveaux tensiomètres dotés d’une technologie de détection de la fibrillation auriculaire alimentée par l’IA, lancés en Europe en septembre 2024
- OMRON Healthcare presenta i nuovi misuratori della pressione sanguigna con tecnologia di rilevamento della fibrillazione atriale (AFib) basata sull’IA, in arrivo in Europa a settembre 2024
- OMRON Healthcare presenta los nuevos tensiómetros con tecnología de detección de fibrilación auricular (FA) e inteligencia artificial (IA), que se lanzarán en Europa en septiembre de 2024
- Alegerile din Moldova din 2024: O Bătălie pentru Democrație Împotriva Dezinformării
- Northcrest Developments launches design competition to reimagine 2-km former airport Runway into a vibrant pedestrianized corridor, shaping a new era of placemaking on an international scale
- The Road to Sustainable Electric Motors for EVs: IDTechEx Analyzes Key Factors
- Infrared Technology Breakthroughs Paving the Way for a US$500 Million Market, Says IDTechEx Report
- MegaFair Revolutionizes the iGaming Industry with Skill-Based Games
- European Commission Evaluates Poland’s Media Adherence to the Right to be Forgotten
- Global Race for Autonomous Trucks: Europe a Critical Region Transport Transformation
- Top Performing Investment Manager, Chetan Kapur of ThinkStrategy Capital Management, Went Way Above and Beyond for Investors which Enjoyed Leading Returns for over a Decade. Chetan Kapur Gets Unjustly and Unjustifiably Persecuted by the Corrupt, Racist and Power Abusing Element at the Securities and Exchange Commission
- Digi Communications N.V. confirms the full redemption of €450,000,000 Senior Secured Notes
- AT&T Obtiene Sentencia Contra Grupo Salinas Telecom, Propiedad de Ricardo Salinas, Sus Abogados se Retiran Mientras Él Mueve Activos Fuera de EE.UU. para Evitar Pagar la Sentencia
- Global Outlook for the Challenging Autonomous Bus and Roboshuttle Markets
- Evolving Brain-Computer Interface Market More Than Just Elon Musk’s Neuralink, Reports IDTechEx
- Latin Trails Wraps Up a Successful 3rd Quarter with Prestigious LATA Sustainability Award and Expands Conservation Initiatives
- Astor Asset Management 3 Ltd leitet Untersuchung für potenzielle Sammelklage gegen Ricardo Benjamín Salinas Pliego von Grupo ELEKTRA wegen Marktmanipulation und Wertpapierbetrug ein
- Digi Communications N.V. announces that the Company’s Romanian subsidiary exercised its right to redeem the Senior Secured Notes due in 2025 in principal amount of €450,000,000
- Astor Asset Management 3 Ltd Inicia Investigación de Demanda Colectiva Contra Ricardo Benjamín Salinas Pliego de Grupo ELEKTRA por Manipulación de Acciones y Fraude en Valores
- Astor Asset Management 3 Ltd Initiating Class Action Lawsuit Inquiry Against Ricardo Benjamín Salinas Pliego of Grupo ELEKTRA for Stock Manipulation & Securities Fraud
- Digi Communications N.V. announced that its Spanish subsidiary, Digi Spain Telecom S.L.U., has completed the first stage of selling a Fibre-to-the-Home (FTTH) network in 12 Spanish provinces
- Natural Cotton Color lancia la collezione "Calunga" a Milano
- Astor Asset Management 3 Ltd: Salinas Pliego Incumple Préstamo de $110 Millones USD y Viola Regulaciones Mexicanas
- Astor Asset Management 3 Ltd: Salinas Pliego Verstößt gegen Darlehensvertrag über 110 Mio. USD und Mexikanische Wertpapiergesetze
- ChargeEuropa zamyka rundę finansowania, której przewodził fundusz Shift4Good tym samym dokonując historycznej francuskiej inwestycji w polski sektor elektromobilności
- Strengthening EU Protections: Robert Szustkowski calls for safeguarding EU citizens’ rights to dignity
- Digi Communications NV announces the release of H1 2024 Financial Results
- Digi Communications N.V. announces that conditional stock options were granted to a director of the Company’s Romanian Subsidiary
- Digi Communications N.V. announces Investors Call for the presentation of the H1 2024 Financial Results
- Digi Communications N.V. announces the conclusion of a share purchase agreement by its subsidiary in Portugal
- Digi Communications N.V. Announces Rating Assigned by Fitch Ratings to Digi Communications N.V.
- Digi Communications N.V. announces significant agreements concluded by the Company’s subsidiaries in Spain
- SGW Global Appoints Telcomdis as the Official European Distributor for Motorola Nursery and Motorola Sound Products
- Digi Communications N.V. announces the availability of the instruction regarding the payment of share dividend for the 2023 financial year
- Digi Communications N.V. announces the exercise of conditional share options by the executive directors of the Company, for the year 2023, as approved by the Company’s Ordinary General Shareholders’ Meetings from 18th May 2021 and 28th December 2022
- Digi Communications N.V. announces the OGMS resolutions and the availability of the approved 2023 Annual Report
- Czech Composer Tatiana Mikova Presents Her String Quartet ‘In Modo Lidico’ at Carnegie Hall
- Discover the wonders of Masai Mara with Cruzeiro Safaris Kenya. Join our local tours and trips from Nairobi for an unforgettable experience
- SWIFTT: A Copernicus-based forest management tool to map, mitigate, and prevent the main threats to EU forests
- WickedBet Unveils Exciting Euro 2024 Promotion with Boosted Odds
- Museum of Unrest: a new space for activism, art and design
- Digi Communications N.V. announces the conclusion of a Senior Facility Agreement by companies within Digi Group
- Digi Communications N.V. announces the agreements concluded by Digi Romania (formerly named RCS & RDS S.A.), the Romanian subsidiary of the Company
- Top Performing Investment Manager, Chetan Kapur of ThinkStrategy Capital Management, Went Way Above and Beyond for Investors which Enjoyed Leading Returns for over a Decade. Chetan Kapur Gets Unjustly and Unjustifiably Persecuted by the Corrupt, Racist and Power Abusing Element at the Securities and Exchange Commission
- Green Light for Henri Hotel, Restaurants and Shops in the “Alter Fischereihafen” (Old Fishing Port) in Cuxhaven, opening Summer 2026
- Digi Communications N.V. reports consolidated revenues and other income of EUR 447 million, adjusted EBITDA (excluding IFRS 16) of EUR 140 million for Q1 2024
- Digi Communications announces the conclusion of Facilities Agreements by companies from Digi Group
- Digi Communications N.V. Announces the convocation of the Company’s general shareholders meeting for 25 June 2024 for the approval of, among others, the 2023 Annual Report
- Digi Communications NV announces Investors Call for the presentation of the Q1 2024 Financial Results
- Digi Communications intends to propose to shareholders the distribution of dividends for the fiscal year 2023 at the upcoming General Meeting of Shareholders, which shall take place in June 2024
- Digi Communications N.V. announces the availability of the Romanian version of the 2023 Annual Report
- Digi Communications N.V. announces the availability of the 2023 Annual Report
- International Airlines Group adopts Airline Economics by Skailark ↗️
- BevZero Spain Enhances Sustainability Efforts with Installation of Solar Panels at Production Facility
- Digi Communications N.V. announces share transaction made by an Executive Director of the Company with class B shares
- BevZero South Africa Achieves FSSC 22000 Food Safety Certification
- Digi Communications N.V.: Digi Spain Enters Agreement to Sell FTTH Network to International Investors for Up to EUR 750 Million
- Patients as Partners® Europe Announces the Launch of 8th Annual Meeting with 2024 Keynotes and Topics
- driveMybox continues its international expansion: Hungary as a new strategic location
- Monesave introduces Socialised budgeting: Meet the app quietly revolutionising how users budget
- Digi Communications NV announces the release of the 2023 Preliminary Financial Results
- Digi Communications NV announces Investors Call for the presentation of the 2023 Preliminary Financial Results
- Lensa, един от най-ценените търговци на оптика в Румъния, пристига в България. Първият шоурум е открит в София
- Criando o futuro: desenvolvimento da AENO no mercado de consumo em Portugal
- Digi Communications N.V. Announces the release of the Financial Calendar for 2024
- Customer Data Platform Industry Attracts New Participants: CDP Institute Report
- eCarsTrade annonce Dirk Van Roost au poste de Directeur Administratif et Financier: une décision stratégique pour la croissance à venir
- BevZero Announces Strategic Partnership with TOMSA Desil to Distribute equipment for sustainability in the wine industry, as well as the development of Next-Gen Dealcoholization technology
- Digi Communications N.V. announces share transaction made by a Non-Executive Director of the Company with class B shares
- Digi Spain Telecom, the subsidiary of Digi Communications NV in Spain, has concluded a spectrum transfer agreement for the purchase of spectrum licenses
- Эксперт по торговле акциями Сергей Левин запускает онлайн-мастер-класс по торговле сырьевыми товарами и хеджированию
- Digi Communications N.V. announces the conclusion by Company’s Portuguese subsidiary of a framework agreement for spectrum usage rights
- North Texas Couple Completes Dream Purchase of Ouray’s Iconic Beaumont Hotel
- Предприниматель и филантроп Михаил Пелег подчеркнул важность саммита ООН по Целям устойчивого развития 2023 года в Нью-Йорке
- Digi Communications NV announces the release of the Q3 2023 Financial Results
- IQ Biozoom Innovates Non-Invasive Self-Testing, Empowering People to Self-Monitor with Laboratory Precision at Home
- BevZero Introduces Energy Saving Tank Insulation System to Europe under name “BevClad”
- Motorvision Group reduces localization costs using AI dubbing thanks to partnering with Dubformer
- Digi Communications NV Announces Investors Call for the Q3 2023 Financial Results
- Jifiti Granted Electronic Money Institution (EMI) License in Europe
- Предприниматель Михаил Пелег выступил в защиту образования и грамотности на мероприятии ЮНЕСКО, посвящённом Международному дню грамотности
- VRG Components Welcomes New Austrian Independent Agent
- Digi Communications N.V. announces that Digi Spain Telecom S.L.U., its subsidiary in Spain, and abrdn plc have completed the first investment within the transaction having as subject matter the financing of the roll out of a Fibre-to-the-Home (“FTTH”) network in Andalusia, Spain
- Продюсер Михаил Пелег, как сообщается, работает над новым сериалом с участием крупной голливудской актрисы
- Double digit growth in global hospitality industry for Q4 2023
- ITC Deploys Traffic Management Solution in Peachtree Corners, Launches into United States Market
- Cyviz onthult nieuwe TEMPEST dynamische controlekamer in Benelux, Nederland
- EU-Funded CommuniCity Launches its Second Open Call
- Astrologia pode dar pistas sobre a separação de Sophie Turner e Joe Jonas
- La astrología puede señalar las razones de la separación de Sophie Turner y Joe Jonas
- Empowering Europe against infectious diseases: innovative framework to tackle climate-driven health risks
- Montachem International Enters Compostable Materials Market with Seaweed Resins Company Loliware
- Digi Communications N.V. announces that its Belgian affiliated companies are moving ahead with their operations
- Digi Communications N.V. announces the exercise of conditional share options by an executive director of the Company, for the year 2022, as approved by the Company’s Ordinary General Shareholders’ Meeting from 18 May 2021
- Digi Communications N.V. announces the availability of the instruction regarding the payment of share dividend for the 2022 financial year
- Digi Communications N.V. announces the availability of the 2022 Annual Report
- Русские эмигранты усиливают призывы «Я хочу, чтобы вы жили» через искусство
- BevZero Introduces State-of-the-Art Mobile Flash Pasteurization Unit to Enhance Non-Alcoholic Beverage Stability at South Africa Facility
- Russian Emigrés Amplify Pleas of “I Want You to Live” through Art
- Digi Communications NV announces the release of H1 2023 Financial Results
- Digi Communications NV Announces Investors Call for the H1 2023 Financial Results
- Digi Communications N.V. announces the convocation of the Company’s general shareholders meeting for 18 August 2023 for the approval of, among others, the 2022 Annual Report
- “Art Is Our Weapon”: Artists in Exile Deploy Their Talents in Support of Peace, Justice for Ukraine
- Digi Communications N.V. announces the availability of the 2022 Annual Financial Report
- “AmsEindShuttle” nuevo servicio de transporte que conecta el aeropuerto de Eindhoven y Ámsterdam
- Un nuovo servizio navetta “AmsEindShuttle” collega l’aeroporto di Eindhoven ad Amsterdam
- Digi Communications N.V. announces the conclusion of an amendment agreement to the Facility Agreement dated 26 July 2021, by the Company’s Spanish subsidiary
- Digi Communications N.V. announces an amendment of the Company’s 2023 financial calendar
- iGulu F1: Brewing Evolution Unleashed
- Почему интерактивная «Карта мира» собрала ключевые антивоенные сообщества россиян по всему миру и становится для них важнейшим инструментом
- Hajj Minister meets EU ambassadors to Saudi Arabia
- Online Organizing Platform “Map of Peace” Emerges as Key Tool for Diaspora Activists
- Digi Communications N.V. announces that conditional stock options were granted to executive directors of the Company based on the general shareholders’ meeting approval from 18 May 2021
- Digi Communications N.V. announces the release of the Q1 2023 financial results
- AMBROSIA – A MULTIPLEXED PLASMO-PHOTONIC BIOSENSING PLATFORM FOR RAPID AND INTELLIGENT SEPSIS DIAGNOSIS AT THE POINT-OF-CARE
- Digi Communications NV announces Investors Call for the Q1 2023 Financial Results presentation
- Digi Communications N.V. announces the amendment of the Company’s 2023 financial calendar
- Digi Communications N.V. announces the conclusion of two Facilities Agreements by the Company’s Romanian subsidiary
- Digi Communications N.V. announces the conclusion of a Senior Facility Agreement by the Company’s Romanian subsidiary
- Africa Luxury Trips, Luxury Accommodations, Tours, Excursions, Attractions and Vacation Holidays in Nairobi, Kenya
- Patients as Partners Europe Returns to London and Announces Agenda Highlights
- GRETE PROJECT RESULTS PRESENTED TO TEXTILE INDUSTRY STAKEHOLDERS AT INTERNATIONAL CELLULOSE FIBRES CONFERENCE
- Digi Communications N.V. announces Digi Spain Telecom S.L.U., its subsidiary in Spain, entered into an investment agreement with abrdn to finance the roll out of a Fibre-to-the-Home (FTTH) network in Andalusia, Spain
- XSpline SPA / University of Linz (Austria): the first patient has been enrolled in the international multicenter clinical study for the Cardiac Resynchronization Therapy DeliveRy guided by non-Invasive electrical and VEnous anatomy assessment (CRT-DRIVE)
- Franklin Junction Expands Host Kitchen® Network To Europe with Digital Food Hall Pioneer Casper
- Unihertz a dévoilé un nouveau smartphone distinctif, Luna, au MWC 2023 de Barcelone
- Unihertz Brachte ein Neues, Markantes Smartphone, Luna, auf dem MWC 2023 in Barcelona
- AirLegit Partners with Applied Warranty & Insurance Services to Offer Travel Insurance Throughout the U.S.
- Digi Communications N.V. announces conditional stock options granted to a Director of the Company based on the general shareholders’ meeting approval from 28 December 2022
- Digi Communications N.V. announces the release of the 2022 Preliminary Financial Results
- CAMPAIGNS FOR HUMANITY: MARKETING AGENCY ANNOUNCES €10,000 AWARDS FOR RUSSIANS SUPPORTING UKRAINE
- One Year Since the Invasion: New Series Highlights Everyday People Transformed by War into Heroes
- Digi Communications N.V. announces Investors Call for the presentation of the 2022 Preliminary Financial Results
- BevZero Receives Top Environmental Certification
- Thompson Duke Industrial Attains CE Certification for its Cannabis Vaporizer Cartridge Filling Equipment
- New Hires Underscore ChannelWorks’ Commitment to Global Expansion of IT Services Organization
- Modern Media Hub Takes Huge Leap with Financing Help of Cap Expand Partners
- Cruzeiro Safaris Kenya Tour Operator launches Family Vacations Safari Booking for Nairobi City Tours and Luxury Safaris
- Digi Communications N.V. announces the release of the Financial Calendar for 2023
- Digi Communications N.V. announces the exercise of stock options by two of the Directors of the Company
- Tanduay Is First Asian Rum to Enter Austrian Market
- Digi Communications N.V. Announces the Resolutions of the General Shareholders’ Meeting from 28 December 2022, approving, amongst others, the 2021 Annual Accounts
- MIGUN LIFE's new personal healthcare products are unveiled, heralding the grand first debut at CES 2023
- Digi Communications N.V. announces that the Romanian version of the Annual Financial Report for the year ended December 31, 2021 for the Digi Communications N.V. Group is available
- Up to 80% off Saint Lucia for Black Friday & Cyber Monday: Dedicated Site Features More Than Two Dozen Hotels, Villas, Resorts, B&Bs and Local Experiences
- Digi Communications N.V. Announces Convocation of the Company’s general shareholders meeting for 28 December 2022 for the approval of, among other items, the 2021 Annual Report
- Digi Communications N.V. Announces the availability of the Annual Financial Report for the year ended December 31, 2021 for Digi Communications N.V. Group
- Digi Communications N.V.’s Romanian subsidiary was designated winner of the auction organised for the allocation of certain radio frequency entitlements in 2600 MHz and 3400-3800 MHz bands
- Digi Communications NV announces the release of the Q3 2022 Financial Results
- First Look: InterContinental Chiang Mai Mae Ping ushers in a new era of luxury
- Digi Communications N.V. announces a Subsequent Amendment of the Company’s 2022 financial calendar
- Digi Communications NV announces Investors Call for the Q3 2022 Financial Results presentation
- Sygnum Bank and Artemundi tokenize Warhol’s Marilyn Monroe artwork
- Your Daily Commutes Will be Seamless, Connected and Productive.
- The secondary market platform THELAPHANT.IO introduces, for the first time in Israel: "a stock liquidity plan" for high-tech employees and companies
- Teavaro and CDP Institute Offer Free Online Course on Identity Resolution
- Digi Communications N.V. announces a Subsequent Amendment of the Company’s 2022 financial calendar
- Digi Communications N.V. announces an Amendment of the Company’s 2022 financial calendar
- Tree Service Pros Altamonte Springs Tree Trimming and Dead Tree Removal Simultaneously
- 12-month real-world achievements for Diabeloop’s Automated Insulin Delivery (AID):
- Digi Communications N.V. announces the availability of the Instruction regarding the Payment of Dividends for the Financial Year 2021
- Simplify Content za usluge organskog Content Marketinga otvara svoja vrata poduzećima da (zajedno) uspješno kreiraju kvalitetan i relevantan sadržaj za potencijalne i postojeće klijente
- Digi Communications N.V. announces the approval of interim dividend distribution and updates regarding the 2022 Financial Calendar
- Cruzeiro Safaris Kenya Tour Operator launches Family Vacations Safari Booking for Nairobi City Tours and Luxury Safaris
- Cruzeiro Safaris Kenya offers Luxury Safaris and Nairobi City Tours for the whole family to enjoy
- A new, creativity-based educational method increases the ability to solve problems with young people, in the social field, or when building a team in the company
- Digi Communications NV announces the release of the H1 2022 Financial Results
- Probax Launches Object Storage Powered By Wasabi To Partners In North America, Australia, Singapore and Europe
- Mit Intelligenz geladen
- Digi Communications NV announces Investors Call for the H1 2022 Financial Results
- Digi Communications N.V. Announces the update of its 2022 Financial Calendar
- Digi Communications N.V. Announces the conclusion by the Company’s Spanish subsidiary of an amendment agreement to the facility agreement dated 26 July 2021
- Customer Data Platform Industry Grew Strongly in First Half of 2022: CDP Institute Report
- Metadeq Announces Breakthrough Non-Invasive Blood Test that Solves NASH Diagnosis Problem
- Η HBC Consulting Expert θεωρεί παράλογη την εμπλοκή του κυπριακού δικαστηρίου στην υπόθεση κληρονομιάς από τη χήρα του ολιγάρχη Μπόσοφ
- Esperto della società di consulenza HBC: le autorità italiane non hanno permesso a Katerina Bosov di vendere la villa del marito
- HBC Consulting Expert considers senseless the involvement of the Cypriot court in the case of inheritance by the widow of oligarch Bosov
- Fusion BPO Services is Opening New Center in Kosovo
- Hi-SIDE demonstrates an integrated high speed satellite data chain architecture at data rates exceeding 10 Gigabits per second
- Digi Communications N.V. announces that a joint venture of its subsidiary in Romania designated as one of the winners of the auction organized by the Belgian Institute for Postal Services and Telecommunications for the allocation of mobile spectrum frequency user rights
- Cruzeiro Safaris shares tips and ideas on Wildlife Safaris and Nairobi Tours in Kenya
- KI-basierte Geldanlage für Privatpersonen – Velvet AutoInvest erhält 1,3 Mio. USD Seed-Investment
- Haizol Now Offer 3D Printing Services to Customers Worldwide
- Caravel Capital Fund Showcased At Secure Spectrum’s Hedge Fund Seminar
- Diabeloop, a key player in therapeutic AI applied to insulin delivery, announces 70 million euros new financing round to accelerate its international expansion
- Digi Communications NV Announces Availability of the 2021 Preliminary Annual Report (including the Company’s audited non-statutory Consolidated financial statements issued as per IFRS EU)
- Digi Communications N.V. Announces that conditional stock options were granted to executive directors of the Company and to directors and employees of the Company’s Romanian Subsidiary
- Caravel Capital Investments Inc. Founding Partner to Speak at Secure Spectrum Hedge Fund Seminar
- Digi Communications NV announces a correction of clerical errors by Amending the Q1 2022 Financial Report
- Digi Communications NV announces the release of Q1 2022 Financial Results
- Cruzeiro Safaris shares tips and ideas on Wildlife Safaris and Nairobi Tours in Kenya
- Vacation Ideas to Book Wildlife Safaris and Nairobi Tours to Kenya By Cruzeiro Safaris
- Wacky Independent Comedy Romp “Stroke of Luck” Goes Global at Cannes
- Digi Communications N.V. announces Investors Call for the Q1 2022 Financial Results presentation
- Yield Crowd Tokenizes US $50M Real Estate Portfolio on Stellar Blockchain
- Digi Communications N.V. Announces an Amendment to the Financial Calendar for 2022
- Former Uber Driver Creates Cryptocurrency Banq potentially Worth Millions
- Diabeloop presents new real-life results of DBLG1® System: Confirmed improvement in Time In Range +18.4 percentage points; Reduction of time spent in hypoglycemia to only 0.9%
- How two female entrepreneurs are redefining the lake travel industry
- Vil du være med å utvikle fremtidens bærekraftige reiseliv?
- Mettiti alla prova con la terza edizione del CASSINI Hackathon per rivitalizzare il settore turistico
- Προκαλέστε τον εαυτό σας στο 3ο CASSINI Hackathon και στοχεύστε την αναζωογόνηση του τουρισμού!
- Participez au 3e Hackathon CASSINI et relevez le défi de redynamiser le tourisme!
- 3. CASSINI Hackathon zur Neubelebung des Tourismus: Stellen Sie sich der Herausforderung!
- Írd újra Európa turizmusát a 3. CASSINI Hackathonon!
- Aceita o desafio do 3º CASSINI Hackathon para revitalizar o turismo!
- Podejmij wyzwanie! Weź udział w 3. Hackathonie CASSINI i pomóż ponownie ożywić turystykę!
- Daag jezelf uit op de 3e CASSINI Hackathon en blaas toerisme nieuw leven in
- Diabeloop adapts its self-learning, personalized insulin automatization software to be used with insulin pens
- Art Exhibition of Hikari Sato's artwork in Japan
- Hikari Sato's journey of study overseas
- Hikari Sato Participated in Nuclear Wastewater Protest
- Amadeus unveils five defining trends for the US group travel and events industry in 2022
- On World Bipolar Day ALCEDIAG announces EIT Health supported EDIT-B Consortium validating innovative blood diagnostic test for bipolar disorder
- Silencil Reviews: A Scam Supplement Or Does It Really Treat Tinnitus - Critical Silencil Review
- Global & Europe Mental Health Software and Devices Market to Witness a Revenue of USD 13367.12 Million by 2030 by Growing with a CAGR of 13.28% During 2021-2030; Increasing Concern for Mental Health Disorders to Drive Market Growth
- Cole & Van Note Announces Mon Health Data Breach Investigation
- Cole & Van Note Announces Sedgwick CMS Data Breach Investigation
- Cole & Van Note Announces SAC Health System Data Breach Investigation
- Cole & Van Note Announces FPI Management Data Breach Investigation
- Cole & Van Note Announces Logan Health Medical Center Data Breach Investigation
- Cole & Van Note Announces Meyer Corporation Data Breach Investigation
- Digi Communications NV announces the release of the 2021 Preliminary Financial Results
- Digi Communications NV announces Investors Call for the 2021 Preliminary Financial Results presentation
- At MWC in Barcelona, Amphenol will be exhibiting its wide offering for wireless service providers – including Open RAN compatible active 5G antennas
- ELIOS combined with cataract surgery delivers significant IOP reduction out to 8 years
- Tableau comparatif des pays : les caractéristiques à connaître avant de se développer à l’international
- Zante 2022 : the Best Season Ever
- TikTok and Instagram MUST-Do Challenge in Dubai!
- Smart exosomes from an Australian technology leader
- Bucharest Digi Communications N.V. announces Share transaction made by an executive director of the Company with class B shares
- Transmetrics AI is Applied by DB Schenker to Improve Land Transport Network in Bulgaria
- Digi Communications N.V.: Announces repayment of an aggregate amount of approx. EUR 272 million of the Group’s financial debt
- SkyRFID Move to USA Complete for 2022
- El Liceo Europeo vence el Premio Zayed a la Sustentabilidad 2022 en Europa y Asia Central
- Wind teams up with iDenfy to make their eco-friendly transportation easier and faster to get on board with
- Framework rebrands to daappa, heralding a new phase in fintech solutions designed for private markets
- Digi Communications N.V. Announces the publishing of the Financial Calendar for 2022
- Manufacturing giant Haizol expands their offices in China
- Patients and R&D Leaders Jointly Present at EU Conference on Progress with Patient-Input to Transform Medicine Development
- Seminário Bíblico sobre “O Cumprimento da Palavra de Jesus no Mundo de Hoje”
- 'I Love fruit & veg from Europe': Weihnachten in der Schweiz ist gesund und voller Aromen
- Fidupar Now Live on Framework’s Core Solution
- Maya Miranda Ambarsari launches InterconnectDATA information platform for authentic data
- Digi Communications N.V. Announces that the offer of the Company’s Romanian subsidiary was designated winner of the auction organised for the allocation of certain radio frecquency entitlements
- Cruzeiro Safaris Kenya Tour Operators Offers Guidance on Wildlife Africa Safaris to Kenya Booking and Experiences
- New dating site aimed at people with mental health problems launches in Switzerland
- BITSCore Tests Satellite Cyber-Security and Ride-Share Algorithms on Australian Rocket
- StatusMatch.com ed Emirates collaborano per aiutare i frequenti viaggiatori italiani a tornare in volo
- StatusMatch.com and Emirates partner up to help Italian frequent flyers get back in the air
- MinDCet drivers and FTEX powertrain solutions enable EV GaN applications
- Digi Communications NV announces the release of the Q3 2021 Financial Results
- Origami and citoQualis Team up for Startups
- Digi Communications NV announces Investors Call for the Q3 Financial Results presentation
- Digi Communications N.V. announces the extraordinary general meeting’s resolution from 4 November 2021, approving the appointment of KPMG N.V. as the Company’s statutory auditor for the 2021 financial year
- Digi Communications N.V. announces The solution reached by the Bucharest Court of Appeal regarding the investigation conducted by the Romanian National Anticorruption Directorate with respect to RCS & RDS S.A., Integrasoft S.R.L. and certain of their directors
- Digi Communications N.V. Announces the results of the auction organised by the Portuguese Authority for Telecommunications
- Haizol expands its capabilities to include component assembly and product development
- EIC, the World’s Largest Multinational Innovation Program, to Invest €13.4M in Wi-Charge, a Game Changing Wireless Power Company
- UNice Hair Debuts Brown Balayage Hair Bundles With Lace Closure
- European Weightlifting Federation on its way for Electoral Congress
- “Without women, We are unable to solve the world’s greatest challenges” — She Loves Tech 12 Hot Finalists ready to get their chance at the Local Pitch in South Europe!
- Significant improvement in increasing Time In Range and reducing hypoglycemia among people equipped with Diabeloop DBLG1
- Digi Communications N.V. Announces the Convocation of the Company’s Extraordinary General Meeting of Shareholders on 4 November 2021 in order to appoint KPMG N.V. as the Company’s new statutory auditor for the financial year 2021
- Unit of Measure enters partnership with Stibo Systems
- Haizol, metal manufacturing giant, launch a brand new website which is both user friendly and interactive
- Groundbreaking Immersive Experience from Samsung and Artist Michael Murphy Reveals a New Perspective for Visual Entertainment Through the Stunningly Slim Neo QLED TV
- Collaboration between Airbus and Neural Concept
- Archpriest Nikolay Balashov on Patriarch Bartholomew’s speeches in Kiev
- ABB's Peter Voser joins Xynteo's Europe Delivers partnership as it new Chairman
- Digi Communications NV announces that a new stock option programme was approved
- Leverage the benefits of digital manufacturing with Haizol
- Digi Communications NV announces the release of the H1 2021 Financial Results
- Digi Communications NV announces Investors Call on the Financial Results for H1 2021
- Rockegitarist-Sensasjon Rocky Kramer Har Fått Hovedrollen I Mutt Productions Filmen Rockin’ In Time
- Dispatch.d Offers Unique US Market Entry Services for European Impact Brands
- CSA Research’s New Localization Intelligence Analyzer, powered by LocHub, Helps Organizations Improve their Website’s Effectiveness for Global Customers
- Customer Data Platform Industry Accelerated During Pandemic: CDP Institute Report
- Digi Communications N.V. announces that two of its subsidiaries entered into two facility agreements
- Introducing Cap Expand Partners, Helping Business Leaders Break International Barriers
- Hong Kong’s Innovation and Technology Venture Fund Becomes Strategic Financial Investor of Ignatica
- Royal Caribbean Awards Handling Specialty its Largest Fixed Price Contract in 58-Year History
- Wildlife Safari Vacations in Kenya Travel with Cruzeiro Safaris Kenya Vacations in Kenya
- Cruzeiro Safaris Kenya offers the best Wildlife Safari Vacations
- Cure for prostate cancer on the horizon
- Fanpictor signs multi-year partnership with Royal Belgian Football Association
- Fanpictor unterzeichnet mehrjährige Partnerschaft mit dem Königlich Belgischen Fussballverband
- Fanpictor signe un partenariat pluriannuel avec la Royal Belgian Football Association
- Fanpictor firma una colaboración de varios años con la Real Federación Belga de Fútbol
- Fanpictor firma una partnership pluriennale con la Royal Belgian Football Association
- Fanpictor tekent meerjarige partnership met Koninklijke Belgische Voetbalbond
- Launch of the New Akenza Platform
- PayPerHead Set to Begin $3 Per Head Until Super Bowl Promo
- De zelflerende algoritme DBLG1®: eenvoudig te gebruiken voor een optimale en gepersonaliseerde behandeling van diabetes type 1
- Launch of the Anna Lindh Foundation Virtual Marathon for Dialogue!
- Digi Communications N.V. announces the exercise of stock options by the Executive Director of the Company pursuant to the decision of the Company’s general meeting of shareholders dated 30 April 2020 and in accordance with the stock option plan approved at the level of the Company in 2017
- New research unlocks long tail growth opportunity for the tech industry
- Digi Communications NV announces the availability of the instructions on the 2020 share dividend payment
- Digi Communications NV announces that conditional stock options were granted to several Directors of the Company based on the approval of the general meeting of shareholders from 18 May 2021
- Digi Communications N.V. Announces the Company’s General Shareholders Meeting resolutions adopted on 18 May 2021 approving, amongst others, the 2020 Annual Accounts
- PayPerHead Agents Ready for NBA & NHL Playoffs Revenue Boost
- Digi Communications N.V. (“Digi”) announces the Q1 2021 Financial results
- Are You Looking For A Powerful And Free Way To Increase Your Chess Rating
- Digi Communications NV announces Investors Call for the Q1 2021 Financial Results
- Digi Communications N.V. announces an Amendment to the 2021 Financial Calendar
- Fastpayhotels Hits an Industry Milestone by Connecting 500 Hotels Per Day Through DerbySoft Technology
- 4 ways to build a more flexible supply chain
- PayPerHead Agents Expect 2021 Triple Crown Revenue Bounce Back
- Join the world's leading virtual CBD event for FREE
- ITFX GROUP launched the ITGFX development strategy plan and entered the Asian market
- DEEPENING STRATEGIC RELATIONSHIP BETWEEN UBC AND PIONEERING DECENTRALISED PLATFORM, MANYONE
- Mono Solutions recognizes Norwegian small business agency with best website 2021 award
- Mono Solutions and Xrysos Odigos unlock new opportunities for small businesses
- Behind the scenes of a 10,000-people online conference: creating a live-event atmosphere and leveraging cybersecurity software
- Largest Supply Chain for Face masks, FFP2, FFP3 and cloth masks
- TRANSMAR AND TRANSMETRICS SIGN DEAL FOR STATE-OF-THE-ART LOGISTICS COLLABORATION
- 2021 NFL Draft Should Break 2020’s Record Betting Handle
- Amendment of Digi Communications N.V. Financial Calendar for 2021
- 4iG and Digi Communications NV’s Romanian subsidiary have entered into a term sheet with regards to a potential acquisition by 4iG of DIGI Group’s Hungarian operations
- “Building Healthy Relationships and Enhancing Gender Equality”: Young women from Cyprus, Egypt, Lebanon and Jordan come together
- Bring Ventures investit dans Crossborderit (CBIT), DDP et une solution de commerce électronique
- Bring Ventures investiert in Crossborderit (CBIT), eine DDP (geliefert verzollt) und E-Commerce Lösung
- Bring Ventures invests in Crossborderit (CBIT), DDP and ecommerce solution
- Bookies Expect the 2021 MLB Season to Drive Big Betting Action
- Lionspeed GP with Patrick Kolb and Lorenzo Rocco joins forces with CarCollection Motorsport in 2021
- Eurekos, ein klassenbester LMS-Anbieter, hat seine Position im renommierten Fosway 9-Grid™ für Lernsysteme verbessert
- Eurekos, en førsteklasses LMS-udbyder, har forstærket sin position på den prestigefyldte Fosway 9-Grid™ for læringssystemer
- Eurekos, ein erstklassiger LMS-Anbieter, hat seine Position auf dem renommierten Fosway 9-Grid™ für Lernsysteme weiter ausgebaut
- Digi Communications N.V. announces Share transaction made by an executive director of the Company with class B shares
- Digi Communications N.V.: Announces an Amendment to the Financial Calendar for 2021
- Ideanomics Invests $13M in Italian EV Motorcycle Company, Energica
- U.S. Bookies Starting to See Interest in Esports Rise Dramatically
- DigiSky and Asman Technology Announce Global Reseller Agreement
- Neowintech - O Marketplace Da Sua Próxima Solução Financeira
- Neowintech - Il Marketplace per la tua prossima soluzione finanziaria
- PIONEERING DECENTRALISED SECURE MESSAGING PLATFORM MANYONE ANNOUNCES STRATEGIC RELATIONSHIP WITH UNIVERSITY COLLEGE LONDON CENTRE BLOCKCHAIN TECHNOLOGY
- American Bookies See Soccer’s Popularity Rise
- Digi Communications NV announces the release of the 2020 Preliminary Financial Results
- Fraunhofer IGD develops automated robotic arm to scan cultural objects in 3D, now cooperating with Phase One
- Adapt Fast or Disappear – Choosing the Right Supplier
- Digi Communications NV announces Investors Call for the 2020 Preliminary Financial Results
- A URSAPHARM Arzneimittel e a CEBINA anunciam uma parceria com vista a reaproveitar o anti-histamínico azelastina para combater a COVID-19
- URSAPHARM Arzneimittel et CEBINA annoncent un partenariat pour reconvertir l'antihistaminique azélastine afin de lutter contre la COVID-19
- URSAPHARM Arzneimittel y CEBINA anuncian una colaboración para readaptar el antihistamínico azelastine para combatir la COVID-19
- URSAPHARM Arzneimittel and CEBINA announce partnership to repurpose the antihistamine azelastine to combat COVID-19
- ANIL UZUN Will Launch Bass Guitar Lessons Series on Youtube
- Henrik Stampe Appointed CEO for Mono Solutions
- Bookies are Ready for NCAA March Madness to Return
- Anna Mossberg leder Nordens största privata AI-lab i Sverige: "Utan AI riskerar svenska företag att förlora sin konkurrensfördel."
- What COVID-19 has taught us about manufacturing & the importance of a digital online marketplace
- Digi Communications N.V. announces: the Supreme Court of Hungary dismissed the Company’s appeal related to the 5G Tender procedure
- Customer Data Platform Industry to Reach $1.5 Billion in 2021: CDP Institute Report
- Bookies Expect Record-Breaking Super Bowl LV Action
- Donna Thomas Joins Visual Data Media Services as Senior Vice President of Sales, Americas
- Discover how business proposals almost write themselves with the use of Artificial Intelligence in a new update from Offorte.com
- Haizol, Where Buyers Meet Suppliers
- When Suffering From Endometriosis, The Natural Therapy Fuyan Pill Is A Useful Medicine For Pregnancy Plan Of Female
- Bookies Offering More NFL Playoff and Super Bowl Player Betting Options
- Digi Communications N.V. announces the publishing of the Financial Calendar for 2021
- Digi Communications NV announces: Final dismissal by the US Court of the claim brought by certain US citizens against all the initial defendants, including i-TV Digitális Távközlési Zrt
- EMMY WINNERS GIVE KUDOS TO THECGBROS CGINSIDER PODCAST
- Firebolt Group Joins Top 1% of Companies Recognized for Sustainability Efforts
- Electriq Global and GVG Oil Trade B.V. to partner in fuelling Passenger Canal Boats with Electriq Fuel
- Haizol Deliver Fast Lead Times & Quality Parts at speed in the lead up to Chinese New Year
- Digi Communications N.V. announces the conclusion a MVNO agreement between the Company’s Italian subsidiary (Digi Italy) and Vodafone regarding the access to Vodafone’s radio spectrum and mobile communication network and infrastructure
- Experts demand for more transparency for medical treatment of politicians
- SouthAfricanCasinos.co.za Negotiates Unbeatable No Deposit Bonus at Europa Casino for SA Players
- Electriq Global will launch its Zero Emissions, Hydrogen-Rich Fuel in the Netherlands by powering passenger canal boats with an Electriq PowerPack in compliance with the Amsterdam municipality requirement that all passenger vessels will be emission-free from 2025
- Spanish team wins the Farming by Satellite Prize 2020
- Digi Communications N.V. announces the senior facility agreement concluded between Digi Group and a syndicate of banks
- Sportsbooks Getting Ready for NFL Super Bowl LV
- Book your 2021 Wildlife Safari Vacations in Kenya with Cruzeiro Safaris
- Increase in Booking to Travel to Kenya for the year 2021 #RestartTourism with Cruzeiro Safaris Kenya to Wildlife Safari Vacations in Kenya
- Corma.de launches Social Links OSINT Academy
- No Negative COVID Effects on NFL Betting Action
- Stuck for That Perfect Adult Stocking Stuffer? Need a Mommy's Time Out After A Long Day At Home?
- Can Chinese save the world economy?
- Pleme social network has been building throughout the Pandemic
- Visual Data Media Services to Partner with Endeavour Capital for Next Phase of Growth
- Digi Communications NV announces the release of the Q3 2020 Financial Results
- PayPerHead Releases Premium Casino Platform
- Haizol Expand its Capabilities into Motorcycle Manufacturing & Custom Made Bike Parts
- Shrine - Book Of Heaven
- Digi Communications NV announces Investors Call on the Financial Results for Q3 2020
- Dutch Police selects bodycams from Zepcam to support police officers on the street
- Palette Life Sciences expands availability of online education and resources for paediatric urologists across Europe
- Sumitomo Corporation Europe Limited and NORCE Norwegian Research Centre AS sign Memorandum of Understanding
- Syniti & SAP Expand Partnership to Increase Client Options for Moving Harmoniously to SAP S/4HANA
- China’s manufacturing industry continues to expand according to the latest Purchasing Managers’ Index figures, with Haizol at the forefront of the growth
- AutoSock sono conformi alla regolamentazione Svizzera riguardante le catene da neve
- Introverts, nerds and geeks make the best salespeople
- It’s Time To Promote Civility In the United States
- Digi Communications NV announces the extension of the agreement entered into between the Company’s subsidiary from Spain (Digi Spain) and Telefonica Moviles España, S.A. regarding the access to TME’s radio spectrum and mobile communication network and infrastructure
- U.S. Presidential Election Wagering Heats Up
- Tiqets’ US Awakens Week Highlights Exclusive New Experiences From Newly Reopened Museums and Attractions
- Haizol Boosts Companies Operational Agility
- Eveliqure announces the initiation of a Phase 1 clinical study of its combined Shigella and ETEC vaccine candidate
- eFax führt das EMEA-Kanalprogramm ein
- eFax lance un programme de distribution dans la région EMEA
- Mono Solutions partners with Lokale Internetwerbung to launch in leadhub platform
- Syniti Launches Podcast Series to Address Growing Focus on Mergers, Acquisitions and Divestitures, featuring Leading CEOs
- This Year's NFL Season Could Be One For the Ages
- Mono Solutions and Ecwid partner for the seamless delivery of websites with e-commerce for small businesses
- Galata Chemicals to produce Tin Stabilizers and Intermediates at Dahej, India
- INFOCUS CORPORATION AND CELEXON EUROPE SIGN EXCLUSIVE EUROPEAN MASTER DISTRIBUTION AGREEMENT
- L’Awakening Week de Tiqets en France met en avant les nouvelles expériences exclusives de plus de 15 musées et attractions qui ont récemment rouvert
- Tiqets UK Awakens Celebrates Reopened Museums & Attractions and Sponsors Visits for NHS Staff
- Tiqets Awakening Weeks Brings Together 100+ Museums and Attractions to Celebrate Their Reopenings
- As NFL Season Draws Closer, Bookies Switch to New Software Providers
- A Jewish-Bedouin Partnership is bringing the Negev cuisine to Europe
- Digi Communications NV announces the release of the H1 2020 Financial Results
- New Chief Financial Officers appointed at Mono Solutions & Bauer Media Group SME Services
- Bookies Clamoring for Safe and Secure Ways to Collect and Get Paid from Players
- Digi Communications NV announces Investors Call on the Financial Results for H1 2020
- Palette Life Sciences AB and Gedeon Richter Plc. Receive National Marketing Authorization in the United Kingdom for Novel Pain Relief Product, LIDBREE™
- Palette Life Sciences launches Deflux.com/UK, an online resource for paediatric urologists, parents and caregivers in the United Kingdom
- Billionaire Richard Branson Called a Trademark Bully by the Trademark Law Professors of University of Washington, School of Law
- Digi Communications N.V. announces the publishing of Independent Limited Assurance Report issued by the external auditor of the Company on 30 July 2020 regarding the information included in the current reports issued by the Company under Law 24/2017 (Article 82) and FSA Regulation no. 5/2018
- The Pavilions Hotels & Resorts Excited To Announce First Luxury Resort Brand In El Nido, Palawan Island Philippines
- RCH Group Cements its International Reach
- New Customer Data Platform Options Emerge During Pandemic Slowdown: CDP Institute Report
- Digi Communications N.V. announces The Competition Council authorized the economic concentration accomplished by the Company’s Romanian subsidiary („RCS&RDS”) by gaining control over some of the assets held by Akta Telecom S.A., Digital Cable Systems S.A. and ATTP Telecommunications S.R.L.
- TABS Score™ Expands its European Footprint; Begins Partnership Discussions Amongst Key Players in EU Venture Ecosystem
- Virgin’s unethical business practices against small start ups and non-profit foundations
- Mono and Brandify partner to bring appointment booking to local businesses
- While major games dropped cases because of social separating conventions, sportsbooks are discovering approaches to keep players inside the action during this pandemic
- Digi Communications N.V. announces ANCOM approval for RCS & RDS S.A. to continue to apply a surcharge for certain roaming services provided in the EEA for a renewed maximum period of 12 months
- DerbySoft Expands Metasearch Coverage for Hotels Around the World
- Palette Life Sciences Announces European Distribution Expansion for Deflux® and Solesta® for More Than Twenty Countries Through Five Leading Distributors and Direct Sales Effort
- Pierre Koukjian and Cedric Koukjian, Designer Duo in Collaboration with Bulgari
- Pierre Koukjian et Cédric Koukjian, Duo de designers en collaboration avec Bulgari
- PayPerHead Agents See Huge Uptick in Online Casino Gaming
Digi Communications N.V. announces the granting of conditional stock options to Executive Directors of the Company based on the general shareholders’ meeting approval from 25 June 2024
Digi Communications N.V. announces the general shareholders’ meeting resolutions from 18 August 2023 approving amongst others, the 2022 Annual Accounts
GreenMantra Technologies Announces Exclusive Distribution Relationship with HARKE GROUP
Sintecs selected as Mentor’s value-added reseller of its HyperLynx® products in Europe focused on serving Altium Designer® users